I’ve recently been brushing up on my SQL skills, as I’ve used the language for a while but less so recently. Through this process, I’ve found that I’m comfortable with the topics of complex joins, Common Table Expressions (CTEs), and nested subqueries. However, it was my deep dive into subqueries where I found something new: correlated subqueries. In this post, we’ll explore the intricacies of subqueries, with a spotlight on the often overlooked (at least for me) correlated subqueries.
What is a Subquery?
In SQL, a subquery is essentially a query within another query. It’s a tool that lets you fetch data used in the main query, allowing for more dynamic and flexible data manipulation. Subqueries can return single values, multiple values, or even a full table that the outer (main) query can use.
Imagine you have a database for a bookstore. You want to find the names of all books that are priced higher than the average price of all books in the store. In this case, the subquery calculates the average price of all books, and the outer query uses this result to list books priced above this average.
SELECT book_name
FROM books
WHERE price > (
SELECT AVG(price)
FROM books
)Subqueries are broadly categorized into two types: nested and correlated.
What is a Nested Subquery?
A nested subquery is a self-contained query that can run independently of the outer query. It’s executed first, and its result is passed to the outer query. This setup is useful for breaking down complex queries into more manageable parts and for performing operations that require multiple steps.
Continuing with our bookstore database, let’s say you want to find the name and price of the most expensive book. Here, the nested subquery finds the highest price, and the outer query retrieves the name and price of the book(s) that match this value.
SELECT book_name, price
FROM books
WHERE price = (
SELECT MAX(price)
FROM books
)What is a Correlated Subquery?
Correlated subqueries are a bit more complex. Unlike a nested subquery, a correlated subquery cannot run independently, as it refers to columns in the outer query. For every row processed by the outer query, the correlated subquery is executed, making it dynamic and context-sensitive. This is particularly useful for performing row-by-row operations that depend on data in the outer query.
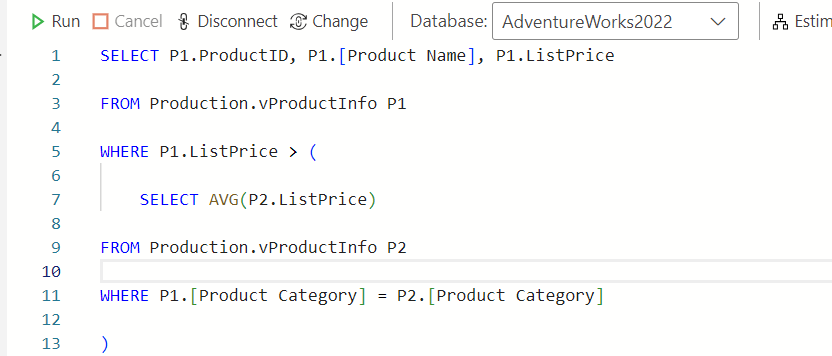
This example uses a correlated subquery to check whether the sales for an author is greater than the average of authors within their same category. The average is calculated for each author, row by row, as the subquery author category is set to be equal to the outer query author category. This is an efficient way to check a criteria, if an author sells more than the average in their category, without needing to return the rows used for that criteria. In this case, we only want to return the author’s name, so a correlated subquery is an efficient way of achieving this task.
SELECT a1.author_name
FROM authors a1
WHERE a1.sales > (
SELECT AVG(a2.sales)
FROM authors a2
WHERE a1.author_category = a2.author_category
)Suppose you want to list all authors who have written at least one book priced above $20. This query demonstrates the use of EXISTS to efficiently check for the existence of records meeting specific criteria within a correlated subquery. Again, we don’t really care about the data within the subquery – we just care that a record exists that meet the criteria defined in the subquery.
SELECT a.author_name
FROM authors a
WHERE EXISTS (
SELECT 1
FROM books b
WHERE b.author_id = a.author_id
AND b.price > 20
)Conclusion
Correlated subqueries in SQL can allow you to solve complex problems more efficiently and with greater clarity. As I’ve continued to refine my SQL skills, embracing correlated subqueries has not only enhanced my querying capabilities but also expanded my appreciation for the language’s depth and versatility.