I had to tackle an issue this week that occurred when I refreshed one of the queries contained in a quarterly report. Here’s the scenario..
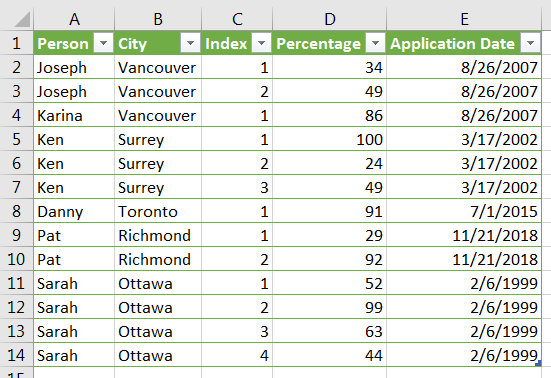
The source data for the query was simple and had only a few columns:
- customer
- some customer attributes
- index with associated percentages
The Index column was created by numbering rows after grouping by customer (Shout out to this Excel Guru blog post for helping me get to this point.)
A clean version of my source data:
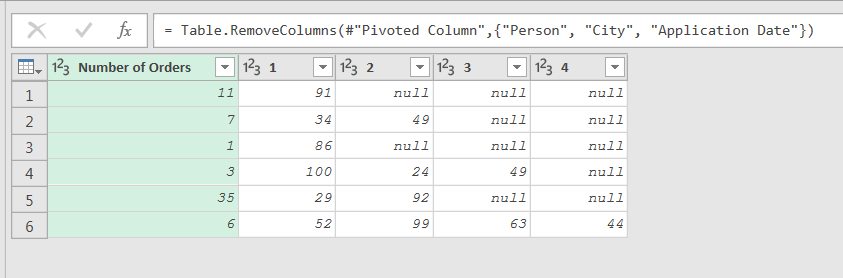
I needed to manipulate this data before landing to the workbook. My first objective was to pivot the Index column and fill with the values from the Percentage column.
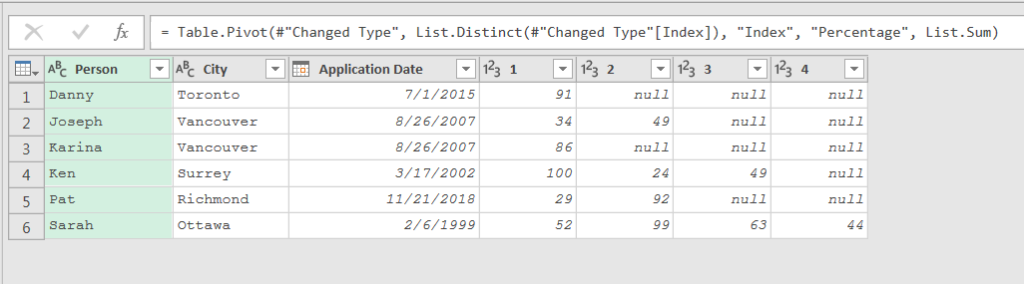
This worked with no issue. Then I needed to merge all of the Index columns to create a column containing a comma separated list of all the percentages.
The first step to achieve this was to change the column types to text. Notice how all four of the column names were hard coded in this step.
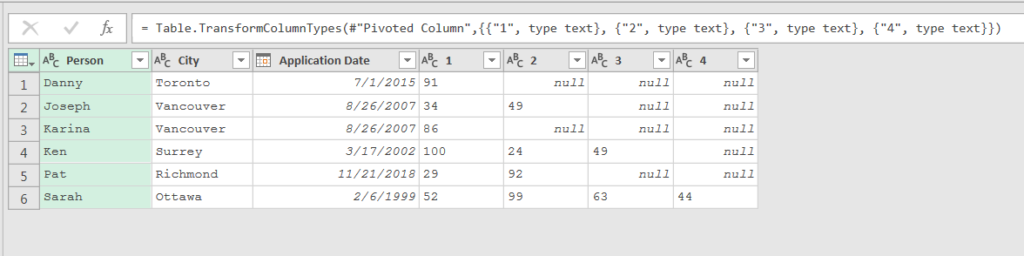
After I changed the type, I selected the columns to merge by a comma separator. Again, notice how the names of the columns to merge were hard coded.
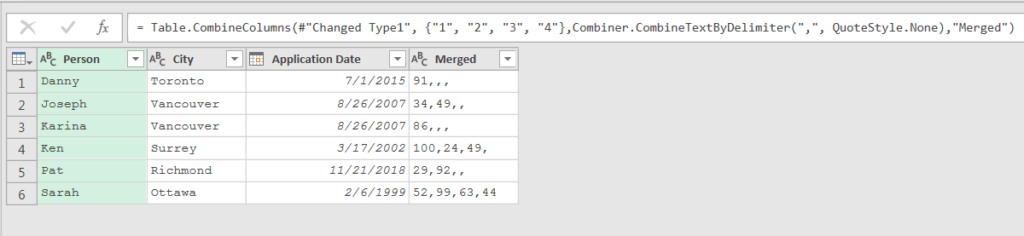
After some additional clean up, this landed the desired outcome to my workbook.
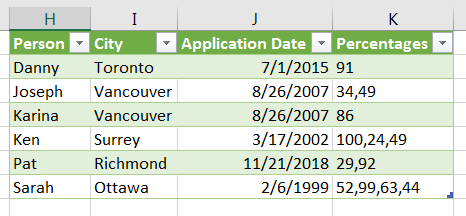
This was all well and good, until it came to the next quarter..
Every quarter, the source data for my query is refreshed with new customers. The most important change in the data to highlight is that the maximum number in the Index column is now 3. Last quarter, the maximum value was 4.
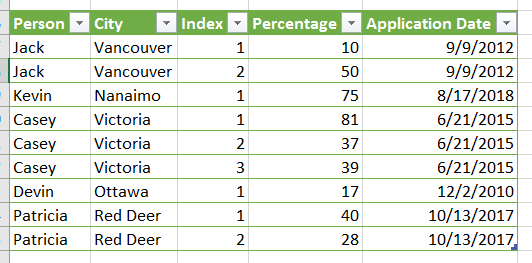
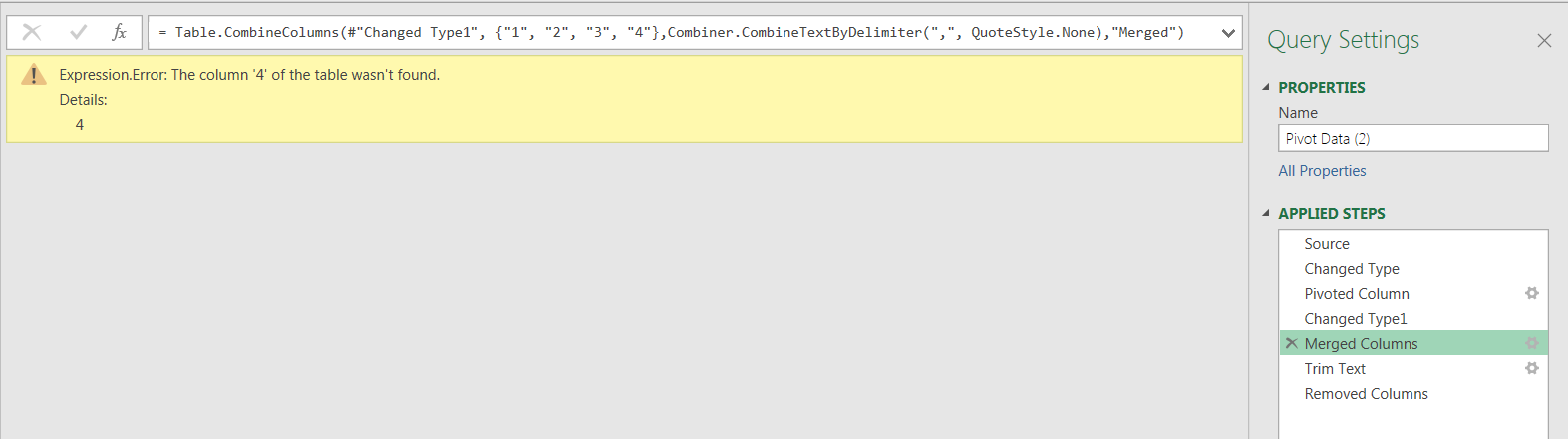
This caused the following error to occur in my query when I tried to refresh.

The #”Changed Type” step was looking for column 4, which no longer exists! This was easy to fix, as I could simply delete the {“4”, type text} clause from the list of columns to change.
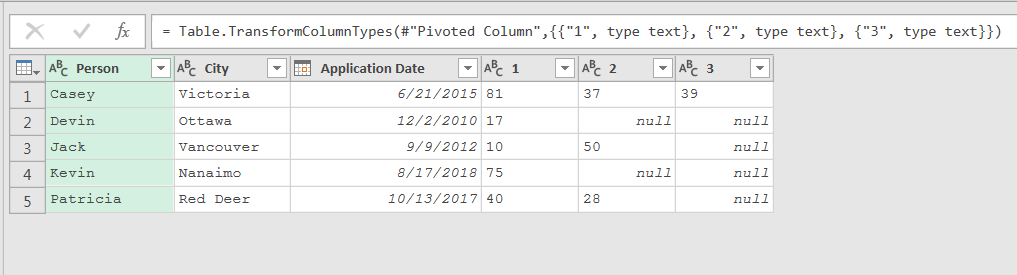
But it errors again!
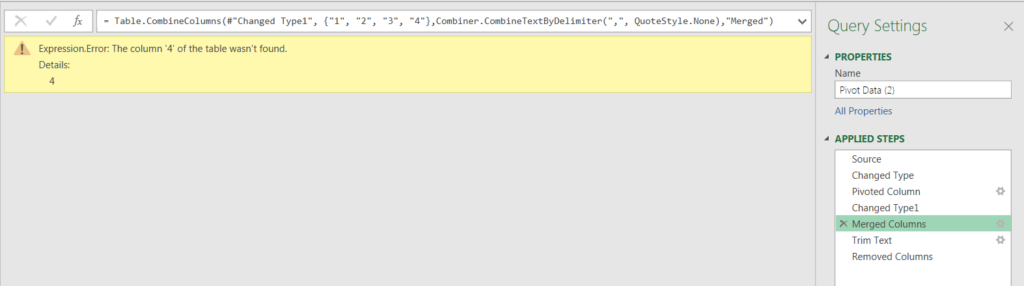
Once again, column 4 was hard coded in the combine columns function. My entire query is outlined below:
I knew I needed to modify the query to dynamically define the columns to change type and merge. I came up with the following solution.
Dynamic(ish) Solution
My first attempt at fixing the initial query was definitely more dynamic than what I started with. I was happy with it for about six hours until I changed it again. I outline the fully complete query, that I’m happy with (for the time being..), in the third section below. But for full transparency, I wanted to include this intermediate step.
The key step to fixing the query was inserting a step immediately after pivoting the index column, named #”Column List”. This step removed the customer and customer attribute columns, leaving only the index columns.
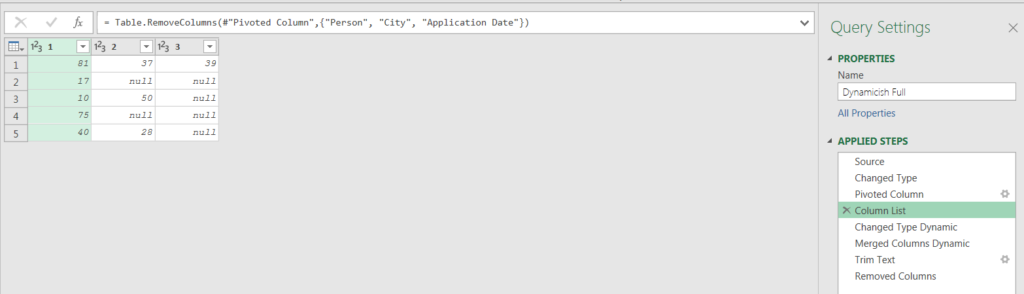
As I explicitly removed the customer columns, this returned all of the index columns. It will do so regardless of how many there are quarter to quarter.
The key assumption here being that we will forever and always only need to remove the three columns hard coded into the remove columns step
.
.
.
(Spoiler: this won’t be the case)
My next step was to change the type of all of the columns defined in the previous step. I found a neat solution in this blog post from the BI Accountant.
The important points that allowed me to do this are:
- Table.ColumnNames() – this function returns all the column names in a table as a list. I called this on the table from my previous step which listed the names of all of the index columns.
- List.Transform() – this function has two arguments: a list and a transformation function. It takes each item in the list and transforms it with the function in the second argument.
I nested these two functions together within the #”Changed Type Dynamic” step. The data for this step is actually from the #”Pivoted Column” applied step (one before I defined the #”Column List”).
I called Table.ColumnNames() on #”Column List” to create the list of columns I wanted to transform. This was the first argument in the List.Transform() function.
The second argument in List.Transform() was to change each column to type text.
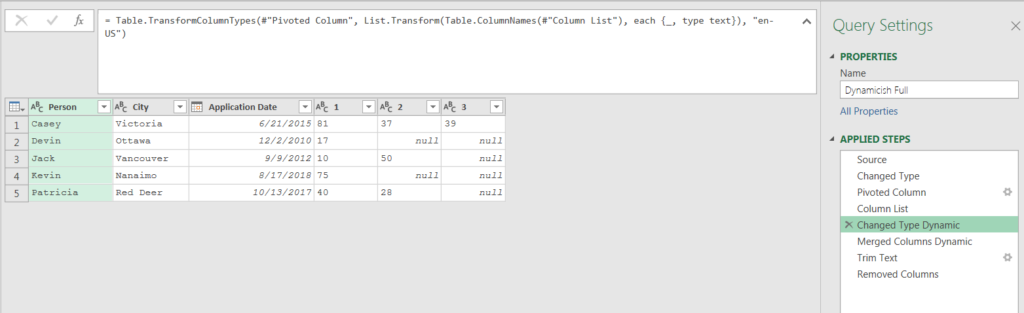
Very nice!! Now I had to merge all of the index columns. I achieved this by once again using the Table.ColumnNames() function on the
#”Column List” step.
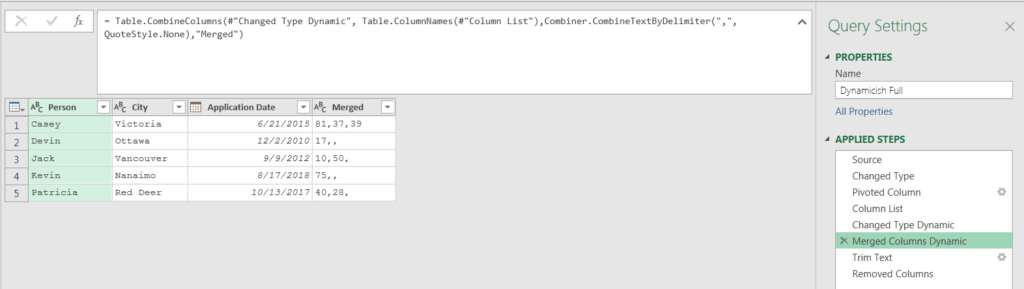
Again, very nice! This worked well and refreshed correctly with the new data.
However.. My query would not work properly if additional customer attributes were added to the source table:
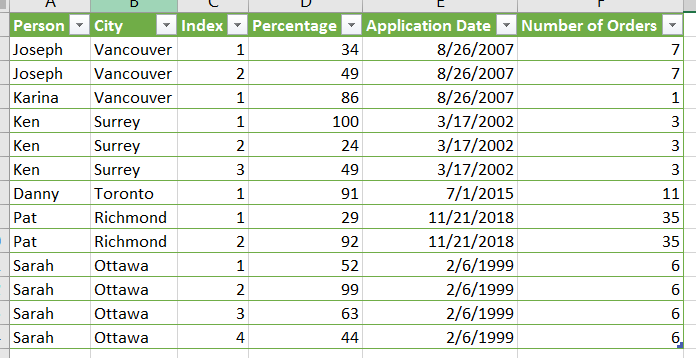
This would result in incorrect data being included in the #”Column List” step. It was particularly problematic with a numeric column like “Number of Orders” being included, as it is hard to distinguish from the percentages that fill the index columns.
Dynamic Solution
To make my solution fully dynamic, I had to change how I was defining my list of index columns to change and merge. To achieve this, my first step was to demote headers after the initial pivot of the index columns.
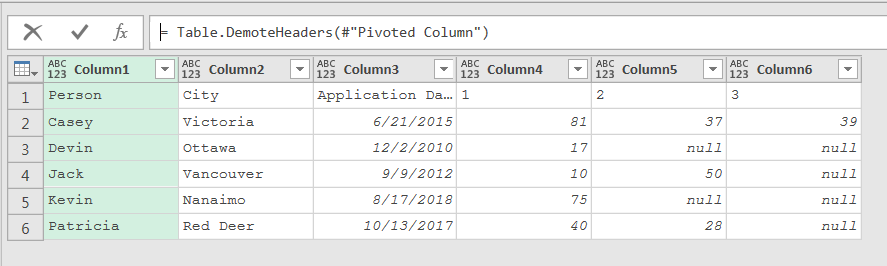
Then I removed all of the data except for the top rows. This left me with a table with one row: Column1 to ColumnN, containing column names in the first row.
My next step was to transpose the table. This resulted in a table with one column containing a row for every column name.
Then I changed the type of the column from any to whole number. I knew that the index column names will always be a number. I also assumed that none of the other column names would be able to be parsed as a number.
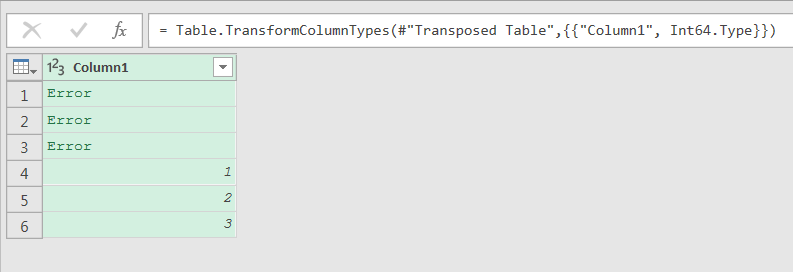
My next step was to remove the errors and transpose the table back.
Now I had a fully dynamic way to define the #”Column List” step, no matter what the other columns in the source data were! My final query is outlined below:
Or you put in the extra line below and call it twice in your code
ColumnsList = List.Buffer(List.Distinct(#”Changed Type”[Index])),
let
Source = Excel.CurrentWorkbook(){[Name=Table]}[Content],
#”Changed Type” = Table.TransformColumnTypes(Source,{{“Person”, type text}, {“City”, type text}, {“Index”, type text}, {“Percentage”, Int64.Type}, {“Application Date”, type date}}),
ColumnsList = List.Buffer(List.Distinct(#”Changed Type”[Index])),
#”Pivoted Column” = Table.Pivot(#”Changed Type”, ColumnsList , “Index”, “Percentage”, List.Sum),
#”Changed Type Dynamic” = Table.TransformColumnTypes(#”Pivoted Column”, List.Transform(ColumnsList, each {_, type text}), “en-US”),
#”Merged Columns Dynamic” = Table.CombineColumns(#”Changed Type Dynamic”, Table.ColumnNames(#”Columns List”),Combiner.CombineTextByDelimiter(“,”, QuoteStyle.None),”Merged”),
#”Trim Text” = Table.AddColumn(#”Merged Columns Dynamic”, “Percentages”, each Text.TrimEnd([Merged], “,”), type text),
#”Removed Columns” = Table.RemoveColumns(#”Trim Text”,{“Merged”})
in
#”Removed Columns”
The question and the solution are very well explained. So I had no problems in adapting the solution to a question raised yesterday in a German forum.
Extremely useful, thank you